- 29 mai 2019
- En Dieter Devriendt
- | 6 min. temps de lecture
- | Source: Motion Control
EDGE COMPUTING
 Calculs sur les appareils
Calculs sur les appareils
A l'instar du 'cloud', 'l'edge' entame maintenant sa progression. En résumé: l'edge computing recourt à la capacité de calcul des appareils dans un réseau local. Ainsi, les données ne doivent pas être aussitôt envoyées vers le cloud, mais peuvent être traitées rapidement sur l'appareil proprement dit. Ceci offre des avantages pour prendre des décisions en temps réel, accroître la sécurité data et réaliser des économies de temps et de ressources.
CONCEPTS
Une définition des concepts est le début de toute bonne explication. C'est pourquoi nous débutons par un petit rafraîchissement des mots-clés (connus ou pas) suivants.
Cloud
Le concept le plus connu dans cette liste est sans nul doute le 'cloud'. Dans ce modèle, des tâches intelligentes sont exécutées sur des serveurs qui transmettent ensuite vers des appareils 'idiots'.
Edge & edge computing
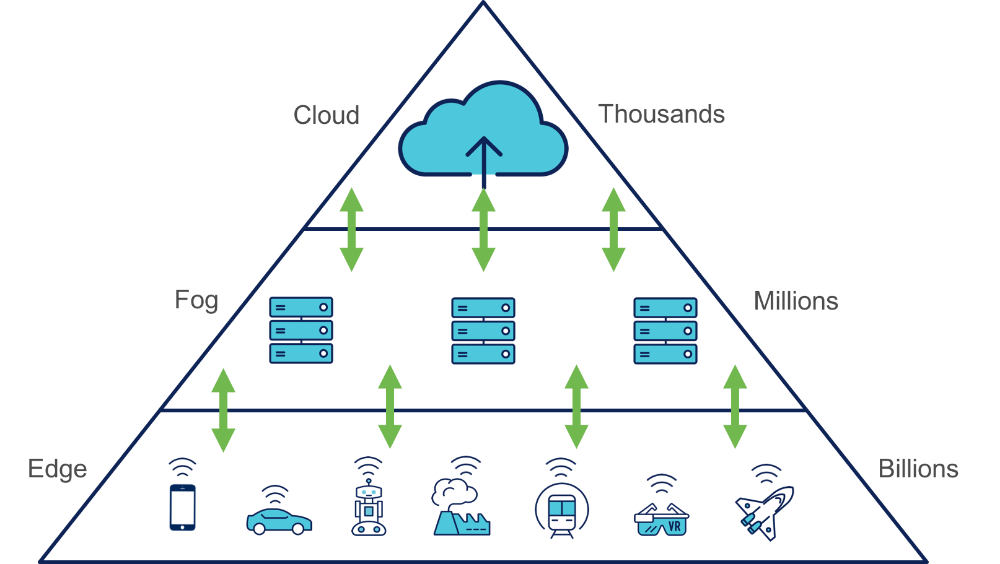
'Edge' renvoie à la limite extrême d'un réseau de technologie d'information: les clients (appli ou système qui accède à un serveur via le réseau). Souvent, ce sont des appareils IoT (Internet of Things) qui traitent les données sur l'appareil au lieu d'envoyer les infos de capteur vers le cloud. L''edge computing' désigne le travail exécuté sur ces appareils; le travail effectué au plus près des données source. Cela offre des avantages, pour la minimisation des données (toutes les données brutes ne rejoignent pas le cloud), mais aussi pour des systèmes très distribués. Des milliers de clients se connectent pour effectuer des parties de travail. C'est la vision idéale de l'edge computing: des milliards d'appareils IoT forment un réseau intelligent qui exécute des tâches qui, autrement, se déroulent dans un énorme data center.
Combinaison edge - cloud
La combinaison entre edge et cloud semble évidente: les systèmes distribués traitent les données sur les appareils eux-mêmes et envoient les résultats vers le cloud pour le stockage et/ou l'analyse ultérieure.
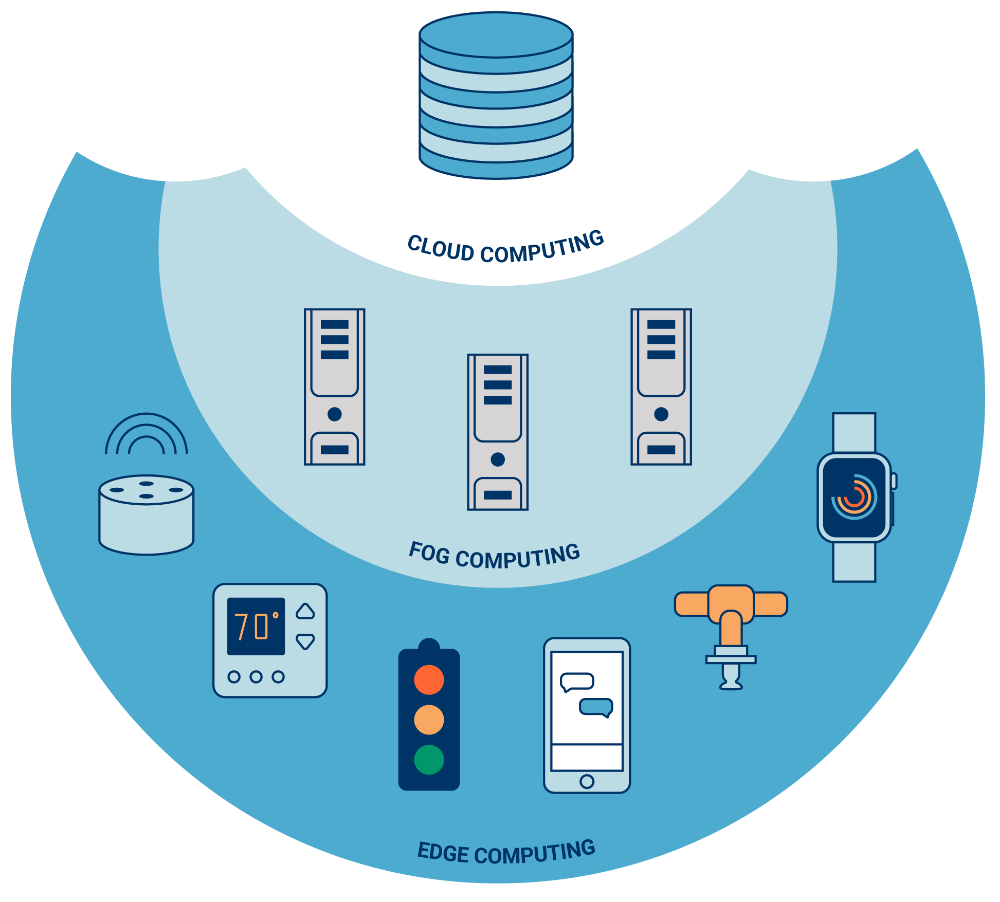
Edge face au fog computing
La tendance vers la décentralisation de la puissance de calcul et du stockage a été initiée il y a quelque temps déjà. L'intelligence décentralisée autorise souvent des actions plus efficaces et évite des coûts inutiles pour la largeur de bande et le stockage. Dans une phase initiale, le paysage IT est devenu de plus en plus brumeux avec la distinction qui s'estompe entre cloud et local, d'où le 'fog'. Si l'aspiration de l'edge et du fog computing est similaire - l'utilisation de la capacité de calcul dans un réseau local au lieu de l'exécution normale dans le cloud - ils diffèrent quant au lieu de traitement des données. L'edge computing se rencontre habituellement sur les appareils sur lesquels sont fixés des capteurs ou sur un appareil gateway physiquement proche des capteurs. Le fog computing, par contre, déplace les activités de calcul vers les processeurs (nodes) qui sont reliés au LAN (local area network) ou dans le hardware LAN proprement dit. Ceux-ci sont donc physiquement plus éloignés des capteurs et actionneurs.
Combinaison fog - edge
Il est possible de combiner fog et edge dans une seule architecture, mais les applications sont assez rares, certainement dans des environnements relativement petits. Le fog peut se comporter comme un seul système dans la couche intermédiaire distribuée, cette approche est donc appropriée aux situations où plusieurs sites doivent être perçus à partir du cloud comme un seul environnement.
MOUVEMENT DE BALANCIER: CENTRAL?
L'accent de la technologie de l'information (IT) oscille depuis ses origines entre centralisation et décentralisation. Cela a commencé par le mainframe computing centralisé. Ensuite, le centre de gravité s'est déplacé vers les réseaux client-serveur décentralisés. Avec le cloud s'est opéré un revirement vers un modèle centralisé. Le local computing - dans l'edge ou le fog - revient au modèle décentralisé. Le modèle décentralisé est nécessaire, parce qu'on attend aujourd'hui de l'infrastructure IT qu'elle soutient un large éventail d'applications IoT et appareils. Le cloud n'est certainement pas fini. De grandes quantités de données d'applications IT traditionnelles continueront probablement à être traitées dans le cloud (en raison de la grande puissance de calcul). Toutefois, cela est réservé aux données qui n'exigent pas un accès direct; le traitement de décisions en temps réel se fait plutôt dans des appareils dans la périphérie. Si vous le comparez à l'exemple humain, le cloud est le cerveau, tandis que l'edge et le fog sont le système nerveux qui exécute des taches très vite, parfois même sans rétroactivité.
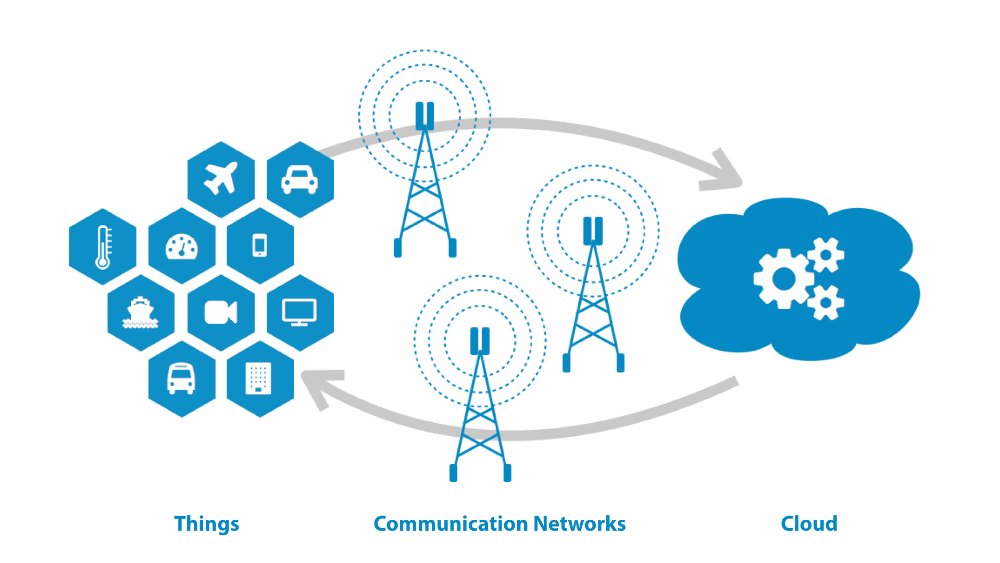 INFRASTRUCTURE EDGE
INFRASTRUCTURE EDGE
Trois exigences doivent être présentes pour l'infrastructure edge.
Partie de la topologie de calcul distribuée
L'edge computing exige une forme de largeur de bande suffisante, cohérente, de connectivité low power. Le Bluetooth est le plus fréquent, mais manque de cohérence. Le wi-fi offre une bonne largeur de bande, mais le court rayon d'action est néfaste pour la cohérence et, en outre, il consomme plus d'énergie que le Bluetooth. La connectivité mobile offre la meilleure cohérence, mais a besoin de beaucoup d'énergie et est confrontée à une largeur de bande parfois limitée.
La solution ultime semble être la 5G, avec une faible consommation d'énergie, une meilleure couverture et une largeur de bande 100 fois plus grande que LTE (4G).
Traitement de l'information
La combinaison du matériel et du logiciel qui traitent l'information, est aussi une exigence. En fonction de la complexité des processus, une microcontroller unit (MCU) suffit pour des tâches simples telles que la filtration des données. L'analyse avancée et l'apprentissage machine exigent la central processing unit (CPU)/ graphics processing unit (GPU) plus high-end et un stockage de plus grande capacité. Le besoin d'une plus grande dynamic random-access memory (DRAM) est inévitable.
Situé près de l'edge
'Près' de l'edge est une notion relative; cela peut aller de l'intelligence intégrée à l'informatique dans la même région.
En guise d'illustration: pour la conduite autonome, l'edge computing a besoin de capteurs dans la voiture pour surveiller le conducteur à partir du tableau de bord, mais également de capteurs qui détectent jusqu'à 100 à 200 m autour du véhicule.
ConclusiOn: La 5g doit y remédier
L'edge computing ne concerne pas simplement des situations où le traitement de l'information s'effectue proche du bord d'un réseau. Il indique plutôt le traitement des données qui s'étend du noyau vers la limite extrême (edge) pour satisfaire aux exigences spécifiques. Actuellement, la meilleure infrastructure pour l'edge computing est conçue uniquement sur des flux de contenu sortants (caching et outstreaming).
Un réseau 5G contribuera à abaisser la barrière de latence et à créer une largeur de bande suffisante. De meilleurs logiciels et processing units peuvent améliorer le respect de la vie privée et la sécurité.
AVANTAGES DE L'EDGE COMPUTING
Sécurité
L'un des avantages majeurs de l'edge computing est la sécurité, accrue parce que les données ne sont pas transférées. L'appareil qui 'a créé' les données, retient les données et les traite lui-même.
Faibles coûts
Un autre avantage de l'edge computing est qu'il aide à garder les coûts bas. La technologie fait économiser du temps et des ressources dans les opérations de maintenance grâce à la collecte et à l'analyse des données en temps réel. Des réseaux à la limite du réseau local procurent des analyses quasi en temps réel qui facilitent l'optimisation des performances et augmentent le temps utilisable.
Chercher l'équilibre
Cependant, l'edge computing comporte un point négatif, à savoir l'exercice d'équilibre entre 'garder les données dans l'edge' et 'envoyez les données vers le cloud central si nécessaire'. Les entreprises peuvent rencontrer des problèmes pour déterminer quand il faut préférer l'un ou l'autre. Du point de vue des coûts, il est souvent plus efficace d'analyser les données localement, mais ce n'est pas toujours le cas. Il vaut mieux traiter les sets de données nécessitant des algorithmes plus sophistiqués dans le cloud.
AVANTAGES DU FOG COMPUTING
Stockage régional
Lorsque le traitement et le stockage des données s'effectuent dans des local area networks avec une architecture de fog computing, cela permet à une organisation de collecter des données de plusieurs appareils dans un stockage régional.
Plus de capacité
Le fog computing permet de collecter des données de plusieurs appareils et dispose donc d'une plus grande capacité de traitement des données.
De plus, le fog a la capacité de traiter des requêtes en temps réel. Donc pas de problème de mise en place quand des millions d'appareils connectés échangent des données.
Coût et cohérence?
La possibilité de connexion avec plusieurs appareils - et donc de traiter davantage de données que l'edge computing - est d'emblée aussi un problème potentiel pour le fog computing.
En effet, il faut davantage d'infrastructure (investissements) et on dépend aussi de la cohérence des données sur un réseau très vaste.
